Usage
Before You Begin
Before you start using lookyloo, you should be familiar with a few concepts, otherwise it won’t make much sense.
We strongly recommend to setup and use your own Lookyloo instance, especially if you’re using it a lot or are submitting URLs you’d rather not have publicly available to anyone using the demo instance.
If you’re fine with that, and just want to give it a try, you can start a Lookyloo capture navigating to our demo instance. On the loaded page click Start a new capture.
Start a New Capture
This is the entry point when you want to investigate a website. You must give a URL, or submit a document, but all the other fields are optional.
URL

The only required field is the URL, which is the URL you want to capture. It might be the index page of the domain to capture:
Or a more complete URL:
If you tick the multiple capture box, you can capture multiple URLs ar once (one per line).
Web enabled document

You can select a file (preferably HTML) on your disk and submit it to Lookyloo.
Browser Configuration
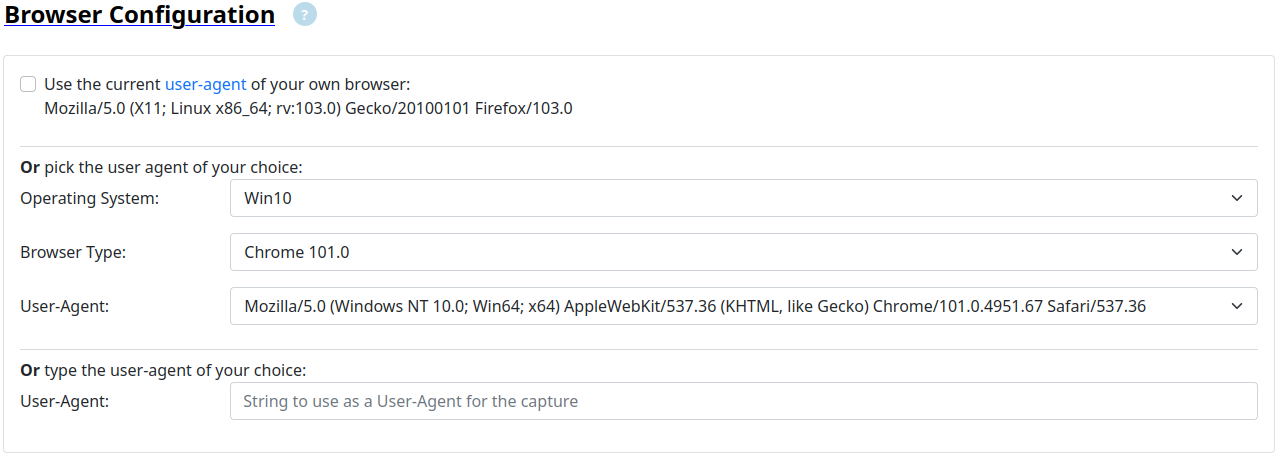
Lookyloo will always use a dedicated browser (playwright), but you can pass it parameters, such as the user agent.
The user agents listed on the page can come from two sources:
-
(Default on a fresh instance) the most recent pre-packaged file.
-
(Default on the demo instance) dynamically based on the user-agents seen by the web interface the day before (if it is configured this way).
In either case, the most frequently used user-agent will be selected by default, it is the one in the last dropdown menu when you load the page.
If you want to use the user-agent of a specific browser on a specific operating system, you can pick one in the lists.
Or you pass the user-agent of your own browser by ticking the box.
Note: If your browser has a very special user-agent, it may leak information about you.
Or you can use the free-text field to pass the string you want as a user agent.
Note: The capture may fail because the websites refuses the User-Agent.
Capture Configuration
This section will allow you to pass more advanced parameters to the capture, please only use it if you know what you’re doing, especially if you’re using the demo interface, as some of them may contain private information.
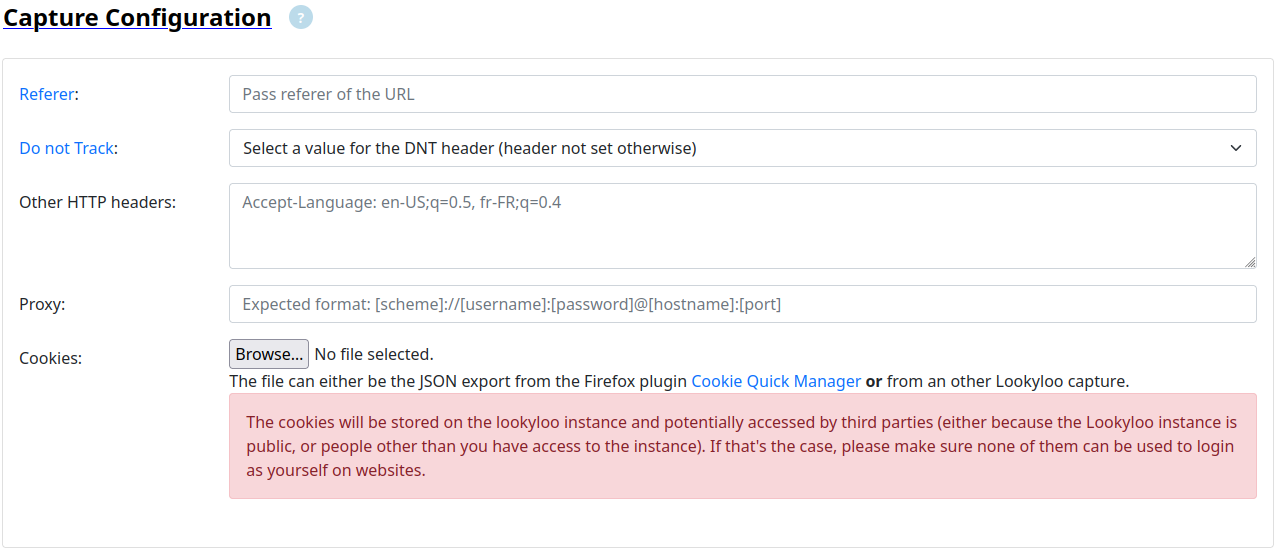
Referer
The referer is optional but it must be a full URL if you want to use it.
Usecase: some websites block requests if they’re not initiated by an internal URL. If that’s the case, pass the required URL in the referer field.
Note: It may not be enough and the website may also require a cookie. If it is the case, see below.
Do not Track
The DNT header is optional and will not be set unless you select one of the value (0, 1, null).
Usecase: the header is deprecated and will be ignored by many websites. It might still be interested to see how different websites handle its presence.
Other HTTP Headers
This is a free text filed where you can pass a list of HTTP headers
to the capture. They must be in the following format: <HEADER_NAME>: <VALUE>, and one per line. Anything else will be ignored.
Usecase: Some websites will redirect you to a specific URL if the Accept-Language header is set by your browser.
Proxy
The proxy is optional but it must follow the format provided in the field if you want to use it.
Usecase: some websites block requests if they’re not initiated from a specific country, or IP block. If that’s the case, you can pass a proxy to the capture.
Note: You need to setup your own proxy server, or you can use tor as a socks5 proxy.
If you use tor with the default configuration, the socks5 proxy will only be listening
on 127.0.0.1.
In order for it to work, the easiest way is to make tor listening on every interfaces
by adding SocksPort 0.0.0.0:9050 in /etc/tor/torrc, restart tor, and then you can pass
socks5://<IP_of_your_host>:9050 in the proxy field of Lookyloo.
If it doesn’t work, try opening http://<IP_of_your_host>:9050 in your browser. You should
have a notification from tor telling you it is a socks5 proxy and not an http proxy.
If you don’t have that, something is incorrect with your tor configuration .
Cookies
It will be empty by default, but please refer to the related documentation in order to initiate a new capture with a pre-refined cookie.
Investigate a capture
As a general statement, if something in unclear, you should move your mouse over the part of the section that doesn’t make sense, and it should display a text giving some explanations. If it doesn’t, please get in touch with us, or keep reading this page.
Nodes
Simple example with the initial URL github.com.
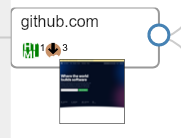
-
The node with a thumbnail of the screenshot is the page as it would be displayed in your browser (after all the redirects). Click on the image to see the screenshot fullscreen.
-
This node contains one single URL, the content of the response is an HTML page
-
The response from the server has 3 cookies

-
In order to get to the landing page, we went from a unencrypted URL (http) to an encrypted one (https)
-
The initial response was empty, it generally means that the redirect was made by the server directly (3XX HTTP code)
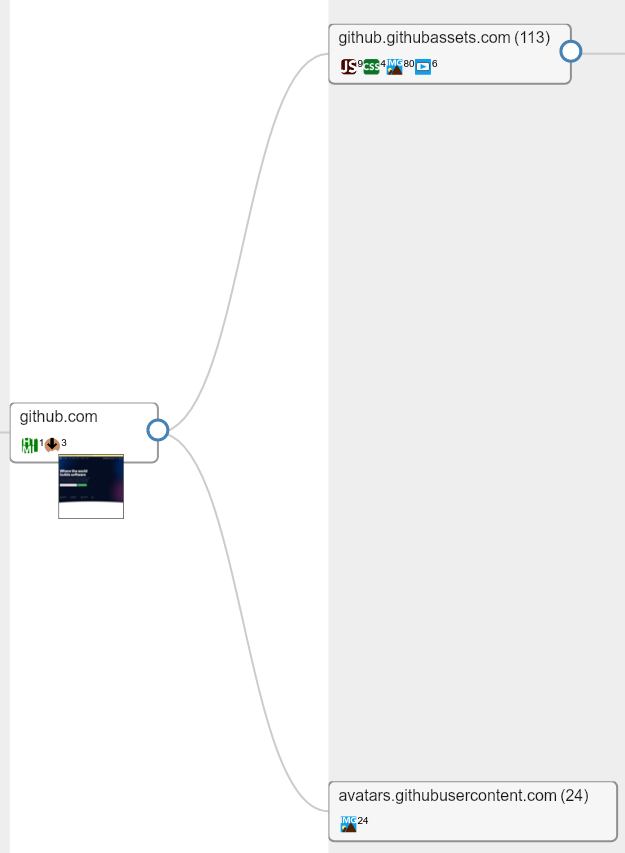
-
The landing page loads resources from two different hostnames (
github.githubassets.comandavatars.githubusercontent.com) -
113 resources are loaded from
github.githubassets.com(9 javascript, 4 CSS, 80 images, 6 videos) -
24 resources are loaded from
avatars.githubusercontent.com(all images)

-
some of the URLs in the node
github.githubassets.comare themselves loading content from URLs ongithub.githubassets.com(8 fonts). It will most probably come from the CSS in the parent node.
In order to investigate it further, we can click on each of the hostnames and open an investigation popup, more on that below.
Hostnode popup
Clicking on the first node github.githubassets.com opens the following pop-up:
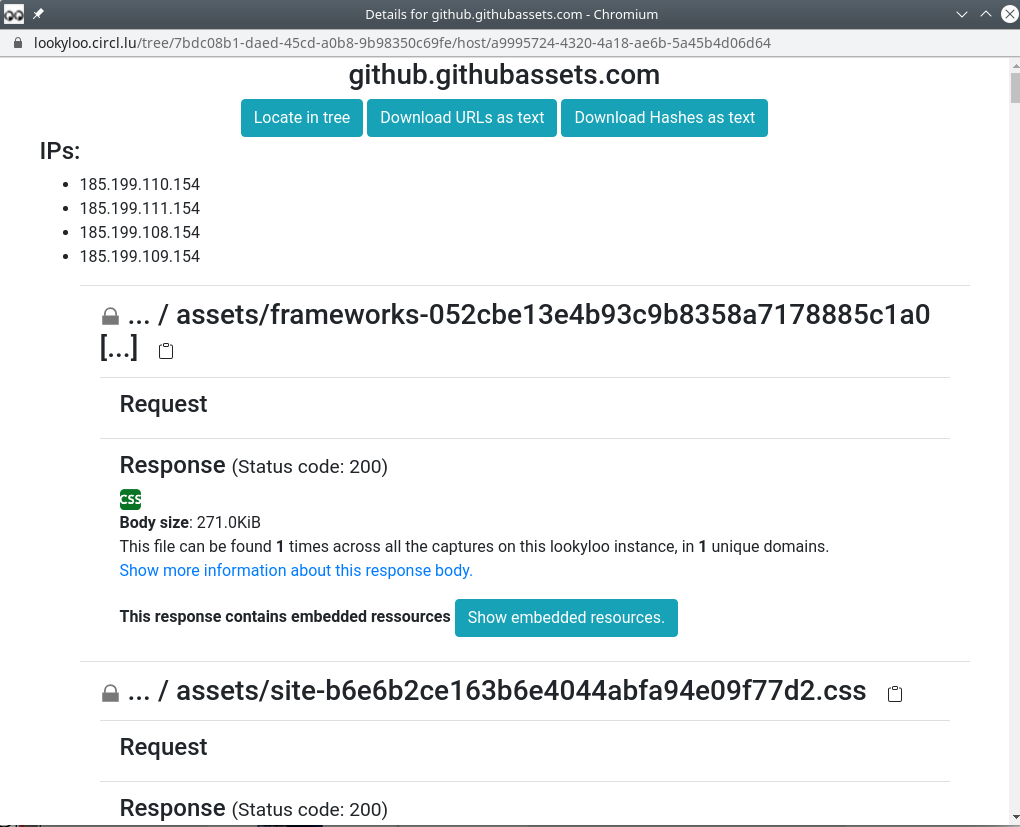
-
You will see every URL aggregated in that node
-
You can do a lot of things from there:
-
Get every resource loaded from the server
-
See if they are present in other captures (correlation by hash)
-
See the HTTP status code of the response
-
Download all the URLs and hashes
-
Get the cookies received of sent for each HTTP request
-
Copy individual URLs
-
If you put pur mouse over the image icon, it will display the image
-